In this article, I will detail a way to solve a common problem: updating databases from web data. This process can be tedious and error-prone when done manually, so a good alternative is to do web scraping via code. However, the ideal situation would be for this code to run “on its own” without the need for someone to be pending to activate this task each time. The solution I present here is to automate this using Github Actions.
Github Actions allows us to execute code periodically, which makes it an ideal tool for this type of task. Next, I will show you how to set up a Github Actions workflow that automates the extraction of data from a website, the processing of that data, and the generation of two CSV files.
This tutorial is aimed at people who have basic knowledge of R and Github.
Github actions allows us, among many other things, to automate the execution of codes using a Github repository. This is of course particularly useful when said code performs a recurring task.
In some way or another, this can be considered as an example of the application of the Continuous Integration (CI) concept from DevOps.
In simple words, to make this work, what you need to do is set up a Workflow, whose content will specify different aspects that are mainly related to a) when the process(es)/job(s) will be executed (Jobs), and b) what will be done and how it will be done
Of course, we assume here that you already have a Github account. If you don’t have one, you should create one before anything else!
Once in your account:
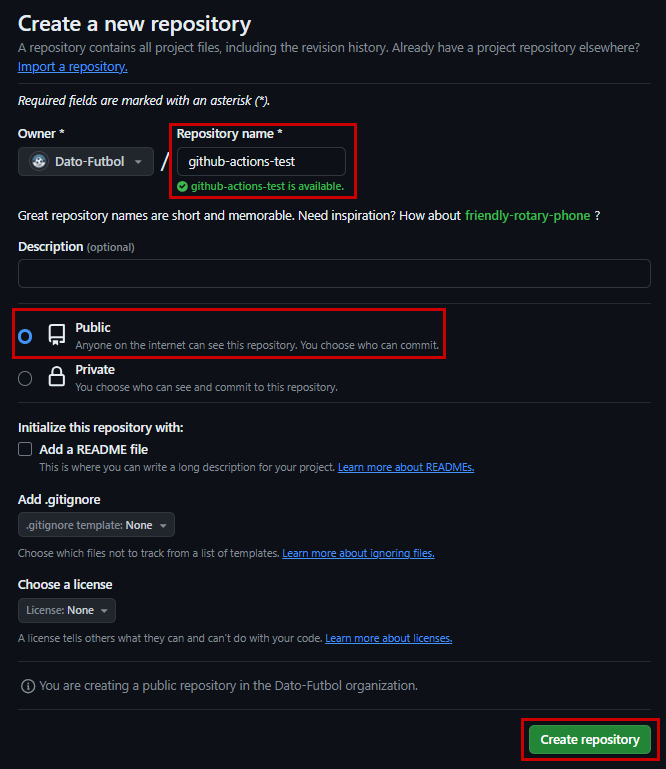
Press “New”
In this repository we will configure the Workflow, add the code that will execute the web scraping and the data process periodically. In addition, that’s where we will store the data in CSV format.
Try to give it an appropriate name based on the objective you are looking for. I called mine gha-chile-games. If you want to try the steps in this tutorial you can use github-actions-test, for example
You can work on the repository either publicly or privately. If you later want to share your code and/or data, I suggest working publicly to facilitate access.
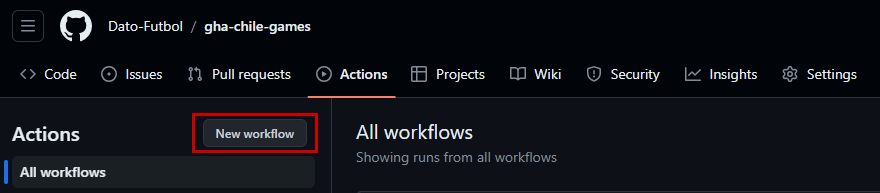
2) Create a new Workflow
Once in the repository go to the “Actions” tab and then press “New workflow”
As you can see, there you will be able to choose from a large number of predefined options, which were designed according to the objective to be achieved. In this case, for didactic purposes, we will configure our own Workflow manually, so you must press “set up a workflow yourself”.
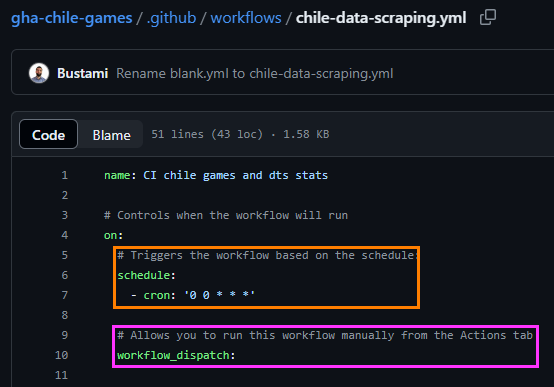
When a Workflow is created for the first time, you will notice that a folder called .github/workflows/ is automatically created in your repository with a file inside called main.yml. This file is empty by default. You can rename it as you prefer as long as it is easy to identify based on what it does (in my case I called it chile-data-scraping.yml). In this folder all the Workflows you create will be saved
Each Workflow has a specific YML file associated with its configuration.
3) Configuring the Workflow
When we talk about configuring the Workflow, we refer to writing a series of instructions in a standard format that will mainly define what we will do, when and how we will do it.
As an example, below we will review each part of the YML file used in the example of the Chile national team matches: “chile-data-scraping”:
Show code
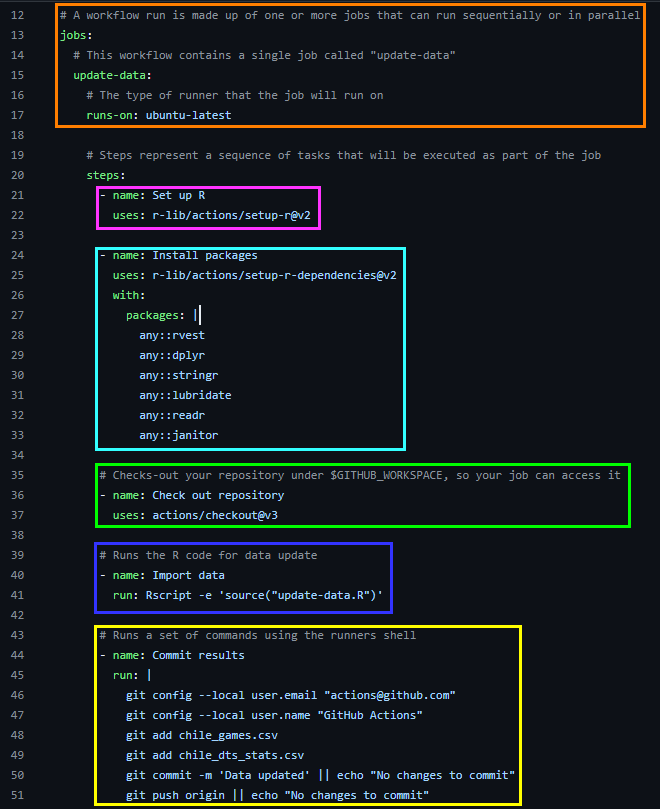
name: CI chile games and dts stats# Controls when the workflow will runon: # Triggers the workflow based on the schedule:schedule:-cron:'0 0 * * *' # Allows you to run this workflow manually from the Actions tabworkflow_dispatch:# A workflow run is made up of one or more jobs that can run sequentially or in paralleljobs: # This workflow contains a single job called "update-data"update-data: # The type of runner that the job will run onruns-on: ubuntu-latest # Steps represent a sequence of tasks that will be executed as part of the jobsteps:-name: Set up Ruses: r-lib/actions/setup-r@v2-name: Install packagesuses: r-lib/actions/setup-r-dependencies@v2with: packages: | any::rvest any::dplyr any::stringr any::lubridate any::readr any::janitor # Checks-out your repository under $GITHUB_WORKSPACE, so your job can access it-name: Check out repositoryuses: actions/checkout@v3 # Runs the R code for data update-name: Import datarun: Rscript -e 'source("update-data.R")' # Runs a set of commands using the runners shell-name: Commit results run: | git config --local user.email "actions@github.com" git config --local user.name "GitHub Actions" git add chile_games.csv git add chile_dts_stats.csv git commit -m 'Data updated' || echo "No changes to commit" git push origin || echo "No changes to commit"
A) When will it run?
After assigning a name to the Workflow using name:, on: configures the options that define when it will run. In this example we have 2 options configured:
[ Schedule a Workflow run with a cron: syntax, whose value “0 0 * * *” in this example states “Run once a day at midnight”. You can read more about cron syntax here. ]
[workflow_dispatch: just enables the option to manually run the Workflow in Github. ]
You can also set a running trigger for other cases such as when a code is committed to the repo or a pull request is created, etc.
B) What we will do and how
This is the core of the Workflow and contains everything we want to do. Keep in mind that for this to work properly, it will run on a server where we need to run an operating system, install programs and packages, etc., in other words we have to enable everything we are going to use.
[jobs: starts the Jobs that make up the Workflow (in this case only one, called update-data). runs-on: specifies the operating system that will be used (in this case the latest available version of Ubuntu, Linux). To set Windows use windows-latest and for Mac macos-latest. ]
The following details the steps we want to take for the single Job configured:
[ Install R: Here we use pre-defined code that is openly available to the community (r-lib/actions/setup-r@v2) ]
[ Install the R packages that we will use in our code: In addition to explicitly specifying the packages, here we also use a pre-defined code to manage the package dependencies (r-lib/actions/setup-r-dependencies@v2). ]
[ Using actions/checkout@v3 checks, among other things, that we have access permissions to the Github repository and that everything is in order to execute the following steps. ]
[ Using run: we run our R code update-data.R in the console. ]
[ Finally, we send some git commands to save the data (the first time it will do it anyway; later, it will only do it when there is new data). In case there are no changes in the data, nothing else is done. ]
Final details
It is important to respect the whitespace and hierarchy of each part (code indentation)
If you are interested, here you can check the R Code for scraping & data processing:
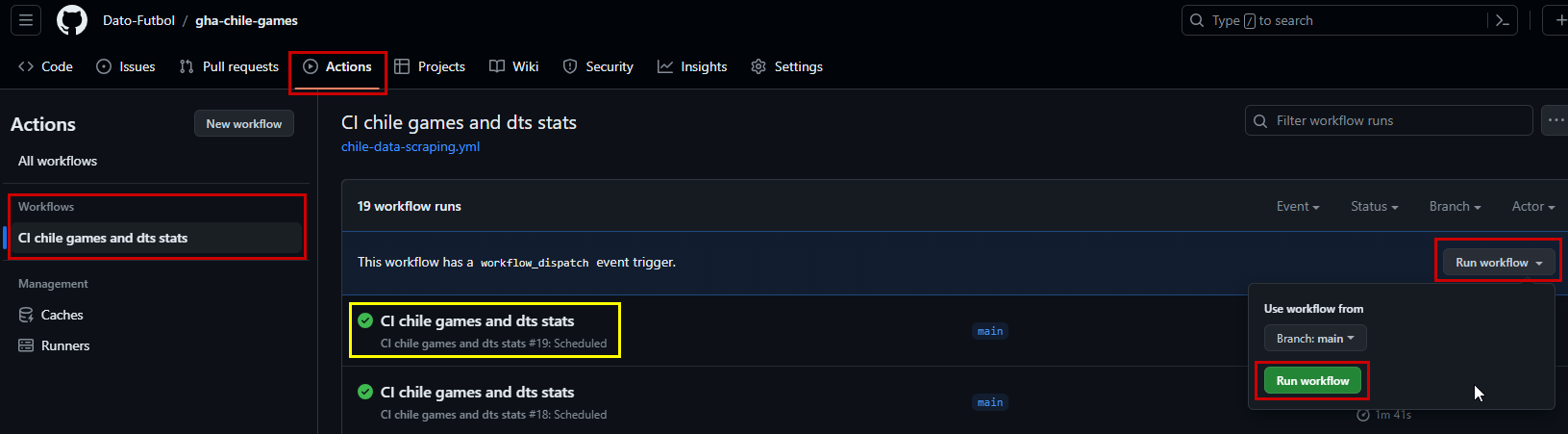
Finally, because our configuration, you have not to wait midnight to know if the whole process works. You can manually trigger the Workflow by clicking “Actions” -> “[the-name-of-the-workflow]” -> “Run workflow” -> “Run workflow” (again, yes), as the following image shows:
If the whole process works fine, a green check will be shown (yellow rectangle on image). You can also click there in the name of the Workflow and check details step by step either meantime the process is running or when it has already finished.
Conclusion
We reviewed in detail an efficient way to keep a database updated based on the configuration of a Github Actions Workflow. In this way, an R code is executed periodically to perform a specific web scraping that updates the CSV with the data when there is new information.
I invite you to explore this tool. Consider that its potential is enormous, not only focused on updating a database. Different tasks can be performed such as the deployment of a Shiny app or rendering and publishing a website, to name a few.